Warehouses, or Compute-Compute Separation (Private Preview)
What is Compute-Compute Separation?
Each ClickHouse Cloud service includes:
- A group of ClickHouse nodes (or replicas) - 2 nodes for a Development tier service and 3 nodes for a Production tier service
- An endpoint (or multiple endpoints created via ClickHouse Cloud UI console), which is a service URL that you use to connect to the service (for example,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443) - An object storage folder where the service stores all the data and partially metadata:
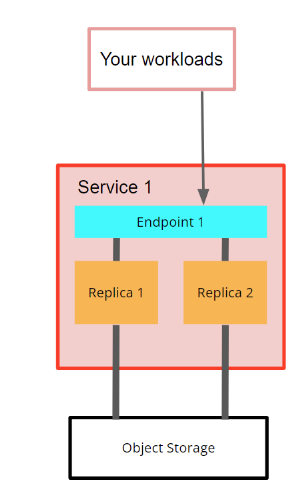
Fig. 1 - current service in ClickHouse Cloud
Compute-compute separation allows users to create multiple compute node groups, each with its own endpoint, that are using the same object storage folder, and thus, with the same tables, views, etc.
Each compute node group will have its own endpoint so you can choose which set of replicas to use for your workloads. Some of your workloads may be satisfied with only one small-size replica, and others may require full high-availability (HA) and hundreds of gigs of memory. Compute-compute separation also allows you to separate read operations from write operations so they don't interfere with each other:
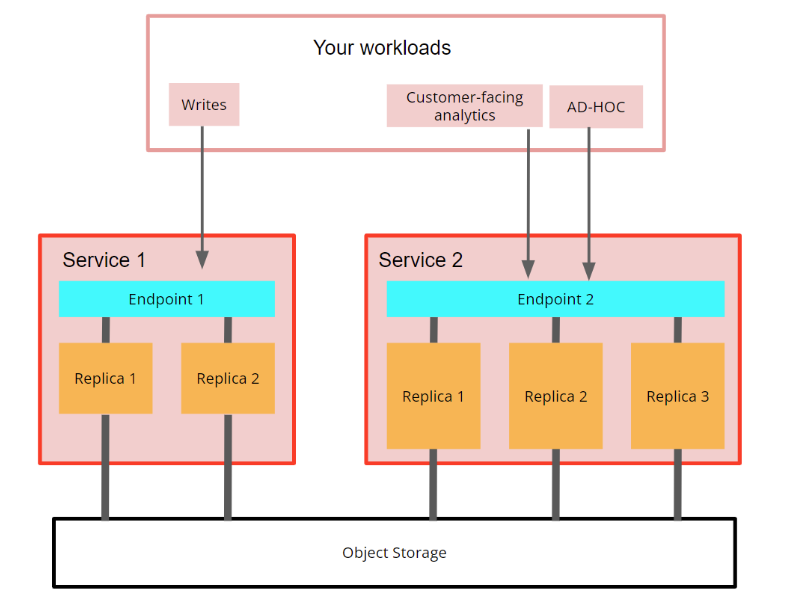
Fig. 2 - compute ClickHouse Cloud
In this private preview program, you will have the ability to create extra services that share the same data with your existing services, or create a completely new setup with multiple services sharing the same data.
What is a warehouse?
In ClickHouse Cloud, a warehouse is a set of services that share the same data. Each warehouse has a primary service (this service was created first) and secondary service(s). For example, in the screenshot below you can see a warehouse "DWH Prod" with two services:
- Primary service "DWH Prod"
- Secondary service "DWH Prod Subservice"

Fig. 3 - Warehouse example
All services in a warehouse share the same:
- Region (for example, us-east1)
- Cloud service provider (AWS, GCP or Azure)
- ClickHouse database version
You can sort services by the warehouse that they belong to.
Access controls
Database credentials
Because all in a warehouse share the same set of tables, they also share access controls to those other services. This means that all database users that are created in Service 1 will also be able to use Service 2 with the same permissions (grants for tables, views, etc), and vice versa. Users will use another endpoint for each service but will use the same username and password. In other words, users are shared across services that work with the same storage:
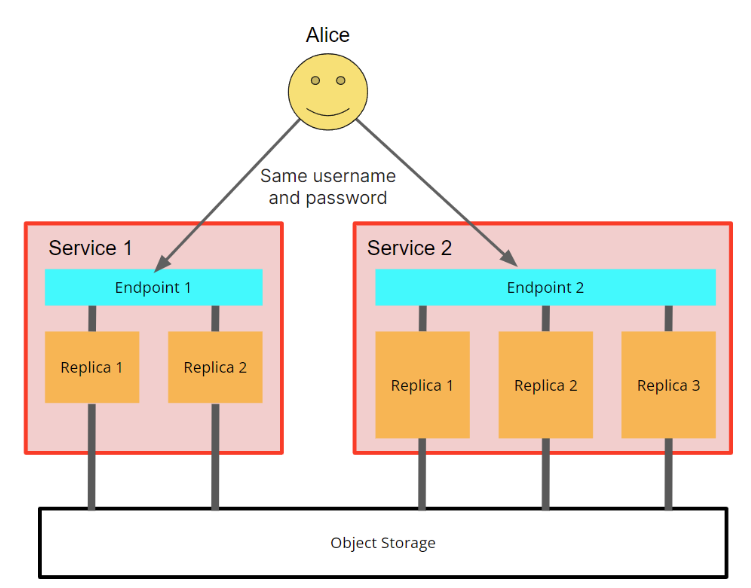
Fig. 4 - user Alice was created in Service 1, but she can use the same credentials to access all services that share same data
Network access control
It is often useful to restrict specific services from being used by other applications or ad-hoc users. This can be done by using network restrictions, similar to how it is configured currently for regular services (navigate to Settings in the service tab in the specific service in ClickHouse Cloud console).
You can apply IP filtering setting to each service separately, which means you can control which application can access which service. This allows you to restrict users from using specific services:
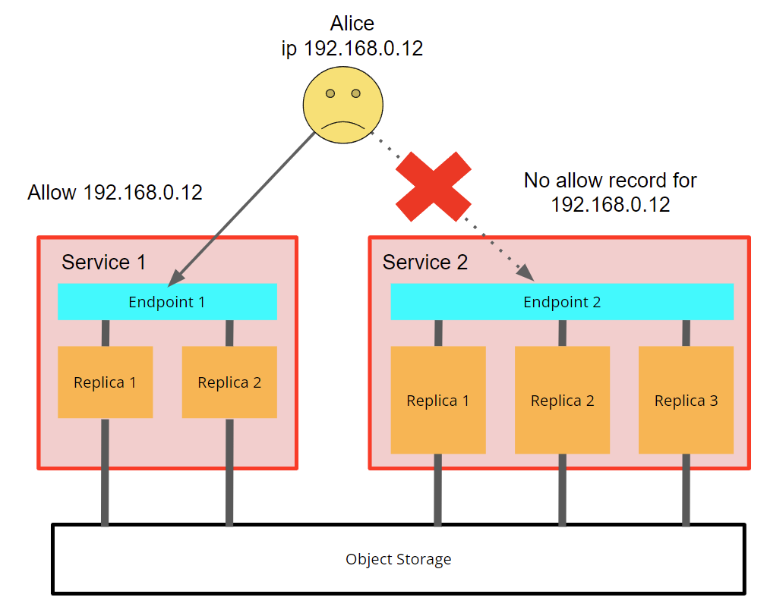
Fig. 5 - Alice is restricted to access Service 2 because of the network settings
Read vs read-write
Sometimes it is useful to restrict write access to a specific service and allow writes only by a subset of services in a warehouse. This can be done when creating the second and nth services (the first service should always be read-write):
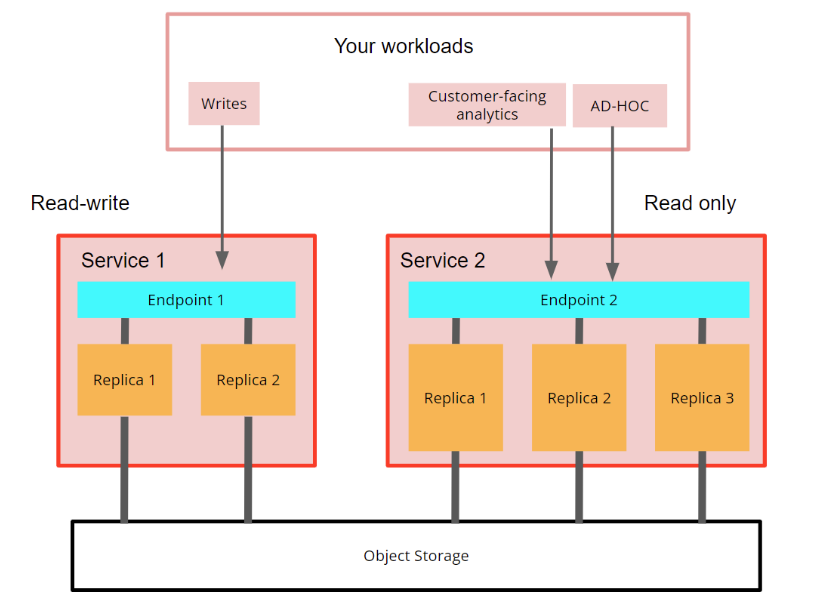
Fig. 6 - Read-write and Read-only services in a warehouse
Scaling
Each service in a warehouse can be adjusted to your workloads in terms of:
- Number of nodes (replicas). Currently, the minimum number of nodes (replicas) is 2.
- Size of nodes (replicas)
- If the service should scale automatically
- If the service should be idled on inactivity (cannot be applied to the first service in the group - please see the Limitations section)
Changes in behavior
Once compute-compute is enabled for a service (at least one secondary service was created), the clusterAllReplicas() function call with the default cluster name will utilize only replicas from the service where it was called. That means, if there are two services connected to the same dataset, and clusterAllReplicas(default, system, processes) is called from service 1, only processes running on service 1 will be shown. If needed, you can still call clusterAllReplicas('all_groups.default', system, processes) for example to reach all replicas.
Limitations
Because this compute-compute separation is currently in private preview, there are some limitations to using this feature. Most of these limitations will be removed once the feature is released to GA (general availability):
Primary (original) service should be recently created or migrated. Unfortunately, not all existing services can share their storage with other services. During the last year, we released a few features that the service will need to support (like the Shared Merge Tree engine), so un-updated services will mostly not be able to share their data with other services. This does not depend on ClickHouse version.
The good news is that we can migrate the old service to the new engine so it can support creating additional services. Reach out to support and we will let you know if your desired service needs to be migrated.
Primary service should always be up and should not be idled (limitation will be removed some time after GA). During the private preview and some time after GA, the primary service (usually the existing service that you want to extend by adding other services) will be always up and will have the idling setting disabled. You will not be able to stop or idle the primary service if there is at least one secondary service. Once all secondary services are removed, you can stop or idle the original service again.
Sometimes workloads cannot be isolated. Though the goal is to give you an option to isolate database workloads from each other, there can be corner cases where one workload in one service will affect another service sharing the same data. These are quite rare situations that are mostly connected to OLTP-like workloads.
All read-write services are doing background merge operations. When inserting data to ClickHouse, the database at first inserts the data to some staging partitions, and then performs merges in the background. These merges can consume memory and CPU resources. When two read-write services share the same storage, they both are performing background operations. That means that there can be a situation where there is an
INSERTquery in Service 1, but the merge operation is completed by Service 2. Note that read-only services do not execute background merges, thus they don't spend their resources on this operation.Inserts in one read-write service can prevent another read-write service from idling if idling is enabled. Because of the previous point, a second service perform background merge operations for the first service. These background operations can prevent the second service from going to sleep when idling. Once the background operations are finished, the service will be idled. Read-only services are not affected and will be idled without delay.
CREATE/RENAME/DROP DATABASE queries could be blocked by idled/stopped services by default (limitation will be removed in GA). These queries can hang. To bypass this, you can run database management queries with
settings distributed_ddl_task_timeout=0at the session or per query level. For example:
create database db_test_ddl_single_query_setting
settings distributed_ddl_task_timeout=0
Pricing
Extra services created during the private preview are billed as usual. Compute prices are the same for all services in a warehouse (primary and secondary). Storage is billed only once - it is included in the first (original) service.
What will happen after the private preview program ends
Once the private preview program ends and the compute-compute separation feature is released in GA, your newly created service(s) will stay as a part of the new compute-compute separation feature. No data or services will be deleted.
Backups
- As all services in a single warehouse share the same storage, backups are made only on the primary (initial) service. By this, the data for all services in a warehouse is backed up.
- If you restore a backup from a primary service of a warehouse, it will be restored to a completely new service, not connected to the existing warehouse. You can then add more services to the new service immediately after the restore is finished.
How to start
To enable compute-compute separation private preview in your organization, please contact the ClickHouse Cloud support team. Once the team enables this feature for you, you will be able to create additional services to any of your existing service in the organization by clicking the plus sign:
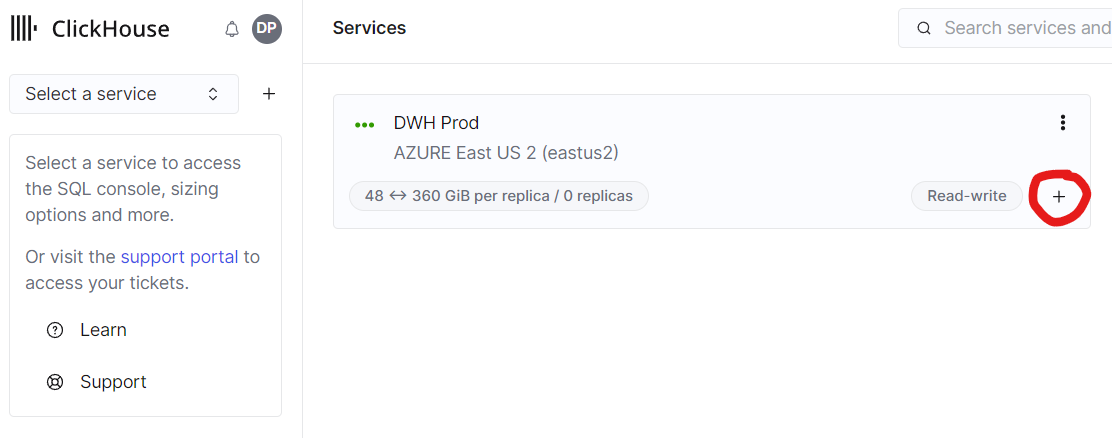
Fig. 7 - Click the plus sign to create a new service in a warehouse